
|
|
Francis Crick What Mad Pursuit. paperback 1988 |
"The originator of the central dogma, Francis Crick, was well aware of genes that didn't encode protein. They don't figure into the central dogma." (Laurence Moran (2023) What's in your genome, chapter 8 paragraph 'Revising the central Dogma?') (my bold)
Exactly: They don't figure in the Central Dogma! That is precisely the problem! Crick omitted noncoding DNA from the Central Dogma. Had he included it in his scheme, a lot of confusion could have been prevented.

|
|
Central Dogma, from: Francis Crick, What Mad Pursuit, page
168. |
Crick could have added an arrow from RNA to for example 'RNA genes'. He did not.
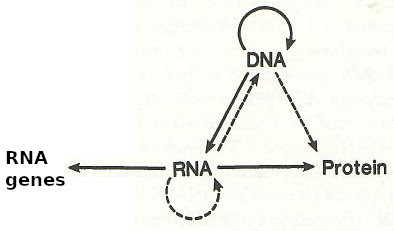
|
|
RNA genes added to Central Dogma
(©GK) |
In this blog I want to explore possible reasons for this omission. They have to do with the historical scientific context of the time that Crick proposed his central dogma. I hope this will show that scientists misinterpreting the Central Dogma are not fools and that Crick himself overlooked non-coding DNA when drawing his Central Dogma diagram. But first a second quote from Laurence Moran:
"Many scientists have a very different view of the central dogma. They were taught, incorrectly, that the real meaning of the central dogma is that DNA makes RNA makes protein and the only function of DNA is to encode protein ... They were somehow led to believe that there was only one kind of gene, namely, protein-coding genes." (Moran, 2023, What's in your genome, Chapter 8) (my bold)
Well, it is certainly not a mystery why many scientists were led to believe
that there was only one kind of gene: there is only one kind of gene in
Crick's illustration of the Central Dogma.
Why did Crick not add RNA genes to his diagram? It is important trying to understand the historical context at the time that Crick proposed his Central Dogma. Traveling back in time is not easy, therefore I use Crick's own account in What Mad Pursuit.
The central problem of biology at the time was: How could genes possibly construct all the elaborate and beautifully controlled parts of living things? It was known that each chemical reaction in the cell was catalyzed by enzymes. This is a defining property of life on earth. Furthermore, it was known before 1953 that enzymes are proteins. Crick realized that the key problem in biology was to explain how proteins were synthesized. In the 1940s a very influential hypothesis was proposed, the 'One gene - one enzyme' hypothesis. The next question was: How do genes control the synthesis of proteins? (Chapter 3 The Baffling Problem, page 33). Obvious today, but at the time it was a problem at the frontiers of science. Further, it was also known at the time that proteins were made of about 20 different amino acids.
After the discovery that DNA consisted of a sequence of bases, the next
question emerged: what is the precise relation between genes and proteins?
Crick proposed the
Sequence hypothesis: the sequence of bases in DNA is a necessary and
sufficient condition for the sequence of amino acids in proteins. Crick:
"Rereading it, I see that I did not express myself very precisely, since I said "...it assumes that the specificity of a piece of nucleic acid is expressed solely by the sequence of its bases, and that is sequence is a (simple) code for the amino acid sequence of a particular protein." This rather implies that all nucleic acid sequences must code for protein which is certainly not what I meant." (Francis Crick, What Mad Pursuit, Chapter 10, page 108).
Then Crick explains that other parts of the DNA sequence could be used for control mechanisms (today: gene regulation) and he even mentions producing RNA for purposes other than coding (today: RNA genes). Crick concluded: "I don't believe anyone noticed my slip, so little harm was done." (page 109). Unfortunately, Crick underestimated the long lasting influence of the famous Central Dogma diagram.
According to Moran the meaning of the Central Dogma diagram is that the
information in proteins cannot get out again. That, indeed, is what Crick
himself says (page 109). Unfortunately, the Central Dogma diagram is a weird
way to illustrate the non-existence of a specific type of information flow.
It is as if one wants to illustrate the absence of something with the
absence of something in an illustration. It isn't manifest. It seems rather
impossible to me to do that [2].
In my view the point of the Central Dogma was to illustrate (albeit in a partial way) the solution of the central question of the time and indeed of all times: how can genes specify proteins? Crick himself expressed this clearly:
"I shall… argue that the main function of the genetic material is to control (not necessarily directly) the synthesis of proteins." [1] (my bold)
The Sequence hypothesis isn't a hypothesis anymore, and it isn't at the frontiers of science anymore, but 'The Sequence' is still and will always be one of the defining characteristics of life on earth [3]. This is certainly not an outdated idea from the pas. Life as we know it is impossible without enzymes (=sequences) and without genes (=sequences) coding for them.
The 'protein universe' is very much at the frontiers of science, new protein structures are discovered today [4].
Appendix (1)
All the following concepts are about protein synthesis:
- Mendelian genes specify discrete phenotypic characters (with the benefit of hindsight).
-
The Sequence Hypothesis states that the sequences of DNA bases specify the sequence of amino acids in proteins. (Chapter 10 Theory in
Molecular Biology)
-
The Central Dogma states the direction of flow of information from DNA to
RNA to protein and not back from proteins (chapter 10)
- The Genetic Code Table specifies which 61 DNA base triplets which amino acid ('sense' codons) and 3 base triplets which specify STOP chain ('nonsense' codons) Chapter 8 and Appendix B.
- The Adaptor Hypothesis (Crick, Chapter 8 page 95) (the implementation of the Genetic Code in specific molecules: tRNA) doesn't make sense without protein synthesis.
Appendix (2)
The terminology used to describe genes makes only sense (!) in relation to protein synthesis:
- sense, nonsense, missense
- sense, anti-sense strand
- positive-sense, negative-sense
- coding strand, template strand
- coding, noncoding
- translation
- STOP/START codons
- the Genetic Code Table
- triplets
- in-frame/out of frame
- ORF: Open Reading Frame
- mRNA: messenger DNA
- tRNA: transfer RNA
- rRNA: ribosomal RNA
Also, the concepts: promoter (DNA sequence to which proteins bind) and enhancer (DNA sequence to which specific proteins bind) make only sense (!) in the context of protein synthesis, direct or indirectly, because they promote or enhance gene expression of protein-coding genes (mainly). Using these concepts implies protein synthesis on the basis of DNA sequences.
However, there are concepts not (directly) related to protein synthesis: base pairing, double helix, transcription, directionality, replication.
Appendix (3)
I wonder whether there is a total absence of any coding signature in non-coding RNA genes. I found it difficult to find clear information about it. For example: do START and STOP codons occur in RNA genes? If so, do they have any effect? Do non-coding RNA genes have a triplet structure? Do single base deletions or insertions have similar effects on RNA genes as on protein-coding genes? (they don't disturb the reading frame). Are there functional RNAs completely independent and unrelated to protein (synthesis)? How did RNA genes originate? Did those they originate from coding sequences or from random sequences?
Notes
-
Matthew Cobb (2017)
60 years ago, Francis Crick changed the logic of biology, PLOS BIOLOGY. Please note "(not necessarily directly)", this is a very ingenious way of including the indirect way of controlling protein synthesis: via enhancers and promoters. (added 22 sep 2023).
- Elsewhere Crick designed another diagram which prevents the dilemma of illustrating the absence of something, see: Larry Moran (2007) Basic Concepts: The Central Dogma of Molecular Biology blog.
- See for example my review of Tibor Gánti (2003) 'The Principles of Life'.
- ‘A Pandora’s box’: map of protein-structure families delights scientists, Nature 13 Dec 2023.
Previous blogs
- The true history of junk DNA 31 July 2023
- Scientists say: 90% of your genome is junk. Have a nice day! Biochemist Laurence Moran defends junk DNA theory. 26 June 2023
It still amazes me how hard people have worked to misunderstand the Central Dogma. If they spent half of the effort in misunderstanding it compared to understanding it there wouldn't be blog posts like yours.
ReplyDeleteThe concept is a very, very simple one.
"The principal problem could then be stated as the formulation of the general rules for information transfer from one polymer with a defined alphabet to another. This could be compactly represented by the diagram of Fig. 1 (which was actually drawn at that time, though I am not sure that it was ever published) in which all possible simple transfers were represented by arrows. The arrows do not, of course, represent the flow of matter but the directional flow of detailed, residue-by-residue sequence information from one polymer molecule to another. "
Crick, "The Central Dogma of Molecular Biology", 1970
https://cs.brynmawr.edu/Courses/cs380/fall2012/CrickCentralDogma1970.pdf
Guess what RNA genes are? They are the residue by residue transfer of sequence information from DNA to RNA. IT IS ALREADY COVERED IN THE DIAGRAM!!!!! The arrow between DNA and RNA is the RNA genes. You no more need RNA genes on the diagram than you need protein genes.
As Moran states, the Central Dogma was NEVER ABOUT DEFINING GENES!!! All the Central Dogma was concerned with is the transfer of sequence information from one alphabet system to the other. Crick stated that DNA sequence to DNA sequence happened. That is DNA replication. DNA to RNA happens. That is transcription, and it INCLUDES RNA GENES. RNA to RNA happens in RNA viruses. RNA to DNA happens in retroviruses.
The two transfers that don't happen are the residue by residue copying of an amino acid sequence into an RNA sequence or a DNA sequence. The other one I am pretty sure doesn't happen is DNA straight to protein.
The Central Dogma was right when it was published, it was right when Crick clarified it again in 1970, and it is still right today. There are no problems with it. The only problem is people want to twist and distort it into things it is not. You might as well be complaining that the Central Dogma does not explain the macroeconomics of the Roman Empire.
Gert,
ReplyDeleteI know that English is not your first language which is probably why the English in Appendix 1 is backwards. For example, it would NOT be correct to say that mammals are dogs since most mammals are not dogs. It would be correct to say that dogs are mammals since all dogs are mammals. Also, cause and effect are a bit mixed up in the first appendix (and in other parts of other appendices). This is how I would have written Appendix 1:
1. A gene is a continuous stretch of functional DNA which can include promoters, coding regions, and regions that are transcribed into RNA's that have function without being translated. A subset of these genes are the classical Mendelian genes with sharp contrast between phenotypes. Most phenotypes are non-Mendelian and are the outcome of many genes interacting.
2. The amino acid sequence of a protein is determined by the nucleic acid sequence of the DNA that codes for it.
3. The Central Dogma states that these types of transfers of residue by residue sequence information do occur:
a. DNA to DNA
b. RNA to RNA
c. DNA to RNA
d. RNA to DNA
e. RNA to protein
AND, that these types of transfer of residue by residue sequence information do NOT happen:
a. Protein to RNA
b. Protein to DNA
c. Protein to Protein
d. DNA to Protein (probably)
4. The position of the first AUG in the mRNA molecule in relation to the 5' end of the mRNA molecule and to sequence motifs (e.g. Shine-Dalgarno sequence) designates the start of the open reading frame. It is the anti-sense codons of tRNA's and their complementary binding to mRNA that determine the rest of the amino acid sequence. Tables in books do not determine protein sequences. The chemistry matters.
5. The Adaptor Hypothesis makes sense of how RNA can give rise to protein sequence. It is the binding of the three base anti-sense codons on the tRNA to complementary RNA sequence and the amino acid attached to the tRNA that allows for the transfer of sequence information from RNA to proteins. Again, the chemistry matters.
Eric, thank you for both contributions!! Anything about Appendix 3?
ReplyDeleteEric, in the meantime, while waiting for your answer, I have found something about what signature functional non-coding DNA could have:
ReplyDeleteUniversal Features for the Classification of Coding and Non-coding DNA Sequences.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2808180/
"In this report, we revisited simple features that allow the classification of coding sequences (CDS) from non-coding DNA. ..."
They propose a statistical test to characterize (protein)coding sequences. Sequences that do not match their criteria are classified as non-coding.
Their method is based on characterizing base frequencies in in the 1e, 2e 3e position of triplets. That is an indirect method. My problem with this is: do functional non-coding sequences have a triplet structure at all? Does that make sense? I am afraid that their method does not bring us any further. What do you think?
First, there is no triplet structure, or at least that is not what molecular biologists call it. Rather, there are open reading frames, or ORFs. This is exactly what the paper you cited focuses on:
Delete"Therefore, should a stretch of DNA start and end with stop codons (TAA, TAG, TGA) separated by a whole number of nucleotide triplets, the question arises as to whether this DNA stretch is coding or not. Hereafter, we will refer to these DNA stretches as “open reading frames” (ORF)."
They talk about the distribution of bases at the 1st, 2nd, and 3rd positions in each codon, but you can't assign those positions until you define the open reading frame. There is no physical or chemical structure in DNA or RNA that defines a triplet structure. Rather, the binding of the tRNA for methionine at the start codon defines the open reading frame and the triplets that follow. In all, there are 6 possible frames within any given sequence since you can start at the 1st, 2nd, or 3rd base and do so on either strand of the double stranded DNA. There can be many potential open reading frames in those 6 frames.
The molecular biology of eukaryotes also complicates matters, namely the presence of introns which introduce false stop codons after the first exon. A mature messenger RNA has these introns removed, and the resulting string of exons contains a long open reading frame that codes for a protein. However, it is really difficult to detect intron and exon sequence in raw DNA sequence from eukaryote genomes. This is why a lot of effort has been put into different algorithms that attempt to identify coding vs. non-coding genes in eukaryote genomes.
Prokaryotes are a bit simpler. There are no introns so you can easily find long open reading frames. However, you need more than open reading frame. You also need a promoter and a ribosome binding site upstream of the coding region, but these are usually easier to find in prokaryote genomes.
Just to get your feet wet . . .
We will be using the Translate tool over at Expasy which looks for all open reading frames in all 6 frames. Paste in the sequence then hit the Translate button to find open reading frames and hit reset to clear the box and paste in a different sequence. Notice that it gives you 6 windows, one for each of the possible 6 frames.
https://web.expasy.org/translate/
Copy and paste in the sequence for human MMP3 found here (exclude the >blahblahbla header):
https://useast.ensembl.org/Homo_sapiens/Gene/Sequence?db=core;g=ENSG00000149968;r=11:102835801-102843609
Copy and paste a random block of about 10,000 bases from the E. coli genome found here:
https://www.ncbi.nlm.nih.gov/nuccore/U00096.2?report=fasta
Then copy and paste a random sequence generated here (set to 9,000 bases with 0.4 GC which is close to the stats for the human MMP3 gene):
https://faculty.ucr.edu/~mmaduro/random.htm
What you will find is that both the human mmp3 gene (introns included) and the random sequence both produce a lot of short open reading frames. They look very similar. However, an equally long stretch of DNA from the E. coli genome has a lot of long open reading frames, some of which actual functional genes.
continued below . . .
DeleteUp to this point, we have been talking about DNA. At the RNA level, it is much, much simpler. In eukaryotes RNA is processed in a way that easily differentiates between coding and non-coding DNA in the vast, vast majority of cases. Coding genes are first spliced (introns cut out and exons joined) followed by polyadenylation which is a process that adds 10's to 100's of A's to the end of the coding RNA. The coding RNA will have 5' and 3' UTR's with a large open reading frame in the middle. Non-coding RNA will not have all of these features. Also worth mentioning, you should find a protein with an amino acid sequence that matches the open reading frame in the mRNA which is a common way of confirming coding RNA. So at the RNA level, they are much easier to differentiate.
Fig 1 in this paper has a good representation of a standard coding RNA:
https://www.sciencedirect.com/science/article/pii/S0378517321003914
As an aside, if you want to sequence the coding RNA in a biological sample from eukaryotes you can use a stretch of T's attached to a magnetic bead. The T's bind to their complementary A tails on the coding RNA and allow you to selectively pull out the coding RNA and wash away the non-coding RNA (mostly ribosomal RNA, tRNA, and miRNA).
To sum all of this up, what matters in coding DNA is the open reading frame and the sequence of the actual RNA's. For non-coding DNA, most of their function is found in their ability to bind complementary sequence in other molecules and forming secondary structures through the binding of complementary bases within the non-coding RNA. There are no missense mutations in non-coding RNA because it isn't translated. The effect of mutations within non-coding DNA has to do with it's function as an RNA molecule, not as a template for translation.
Thanks Eric for your contribution. This is much appreciated.
ReplyDeletehttps://web.expasy.org/translate/
is a nice tool. Thanks for the nice examples.
ORF's in random DNA are very interesting. Somebody called Periannan Senapathy did computer simulations with random DNA in 1994 and reasoned that if the DNA sequence is long enough, useful ORF's will be found, could be genes, etc. He did this without modern tools and without modern biochemical knowledge.
You wrote: "For non-coding DNA, most of their function is found in their ability to bind complementary sequence in other molecules and forming secondary structures through the binding of complementary bases within the non-coding RNA."
so, the only sequence constraint that applies to non-coding DNA and RNA is binding potential to specific proteins and base pairing for secondary structures?