|
| random DNA (source) |
Can a random DNA sequence contain a gene by pure chance? If a 'gene' is defined as a sequence consisting of a number of bases that is divisible by three, starts with a START codon and ends with a STOP codon, then simple statistics show that genes can be found in random DNA. But, do random genes exist in reality?
|
|
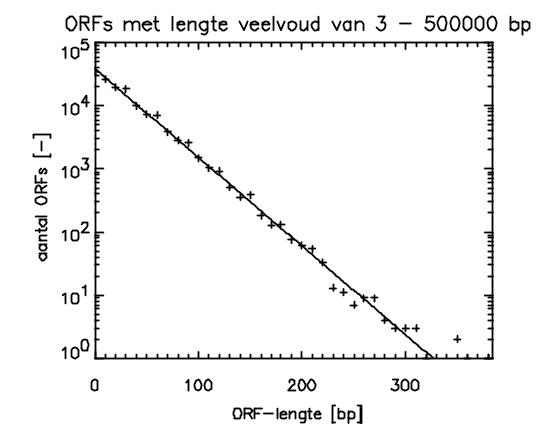
ORF = Open Reading Frame. ORF length distribution of random DNA in base pairs found in random DNA of 50 million bases. Vertical: number of ORFs with a specific length using a logarithmic scale Horizontal axis: ORF length in base pairs [bp] ORF: sequence of triplets between START (ATG) and STOP (TAA) © Rolie Barth |
Yes, short 'genes' can easily be found in random DNA by pure chance if the random sequence is long enough. The presence of START and STOP codons determines the length of the gene. START and STOP codons are triplets and consist of three bases (nucleotides). Everything between the START and STOP must consist of triplet codons. A STOP codon terminates the synthesis of each protein. The distance between a START and a STOP codon equals the length of a potential protein-coding gene. If that length is short, the corresponding protein will be too short to be useful. The START and STOP codons occur by chance in a random sequence. Therefore, the gene length is distributed according to statistical laws. The length of a gene is important. The statistics show that the maximum gene length found in a string of random DNA of 50 million bases is 354 base pairs = 118 triplet codons. See figure above. If transcribed and translated, those sequences would produce a protein of 118 amino acids in length. In the above simulation, most of the hypothetical genes are less than 150 base pairs or 50 amino acids in length. Proteins smaller than 50 amino acids are called peptides. A number of peptides are useful, but most functional proteins in animals and plants are much longer: on average 486 amino acids.
In the above computer simulation, only one STOP codon is used for simplicity. That's why mainly peptides are found. If all 3 STOP codons are used in the simulation, ORFs are almost twice as short [2]. On the other hand, if a random sequence would have the length of the human genome, that is 3.5 billion base pairs or 60 times bigger than in the above simulation, than the maximum length of the hypothetical genes would be 470 bp. That is 1.35x longer [2].
In hindsight, it is not surprising that 'genes' can be found in random DNA. The beauty of the genetic code is that any 3-letter combination of A, T, C, G is a valid codon, including START and STOP codons. That means, that any such a sequence is potentially a protein-coding gene. The similarity between real and random genes is that they consist of a sequence of the same 4 letters A, T, C, G. On that level they cannot be discriminated. The differences lie elsewhere (see below).
Interestingly, from the above computer simulation, several mathematical laws emerge.
- The first law: there is a maximum length of genes when a 'gene' is defined as a sequence between START and STOP, and it consists exclusively of triplets of bases (total length is divisible by 3).
- The second law is: the maximum length of a 'gene' depends on the length of the random sequence. The larger the random sequence, the larger the genes.
- The third law is: gene length is bigger when only 1 STOP codon is used instead of standard 3 STOP codons (results not shown here).
Mathematicians call the graph a Power Law. Please keep in mind that all this is purely mathematics. It depends on the underlying assumptions whether the results apply to living organisms. For now, it seems that genes of useful length could be found in random DNA with the length of the human genome (3.5 billion base pairs).
But does this sort of mathematics apply to the real world? Does random DNA exist in the real world? Yes, it could be. Our genome consists of 90% 'junk'. Junk DNA is not pure random DNA, it has an evolutionary history. It is subject to random mutation and decay. Therefore, it approaches random DNA. So, there are ample opportunities to find genes in junk DNA. Curious genome researchers have searched for functional random genes in real genomes. But first: how do you detect those random genes? How do you discriminate between 'normal' genes and 'random' genes? Again, both are a series of 4 letters in a sequence. Random sequence genes must be novel genes or de novo genes. They are also called orphan genes for obvious reasons. Since they are created from scratch, they do not have identical or similar genes in the genomes of closely related species. Furthermore, the sequence of the putative gene must be present in non-coding DNA of closely related species in the same location on the chromosome. A researcher concluded:
"Although considered an extremely unlikely event, many genes emerge from previously noncoding genomic regions. (..) De novo genes arise from previously noncoding DNA, are short, and are expressed at low levels. (...) While most of the de novo genes are lost, a fraction of them becomes essential. [3]
Intriguingly, the ORFs of de novo genes are shorter than those of evolutionary old genes, but longer than expected by chance according to this researcher. We have seen in the above computer simulation that random genes tend to be smaller than real genes. Even more surprising, de novo genes can become essential.
In humans, at least three human protein-coding genes have emerged since the divergence with chimps some 7 million years ago. These loci are noncoding DNA in other primates (that is part of the definition of random genes). Other studies estimate that 18 such cases are present in a genome of 24,000 protein-coding genes [4]. That's interesting, but the problem with this method is that the noncoding sequences could be the modified descendants of ancient genes or pseudo-genes. So, we cannot be 100% sure that they are truly random.
In 2013 genome researcher Sean R. Eddy proposed the Random Genome Project:
"Suppose we put a few million bases of entirely random synthetic DNA into a human cell. (...). Will it be reproducibly transcribed into mRNA-like transcripts, reproducibly bound by DNA-binding proteins, and reproducibly wrapped around histones marked by specific chromatin modifications? I think yes." [1]
Exactly this experiment has been done recently [5]. Investigators inserted a synthetic DNA sequence in yeast and in mouse cells. In yeast cells, the DNA was being read (transcriptional activity), but the mouse cells did nothing. The researchers concluded that regulatory DNA elements are required in order for the gene to be read. But reading a gene is only the first step. The product (mRNA) must be transported to the cytoplasm and translated by ribosomal machinery and transfer-RNA (tRNA) to a protein. Furthermore, the resulting protein must be able to fold in to a functional 3D form. A further requirement is that the new protein must fit into the existing network of biochemical reactions of the cell and the organism. Of course, it does matter whether the gene is active in every cell of the organism, or just in specific tissues or organs. Also, in what quantities it is produced. And whether it is produced in the embryo or in the adult, in males or in females. A lot of requirements indeed. No wonder that there aren't a lot of genes that originate from random DNA.
The discussion so far is about the origin of new genes from random DNA in real genomes of real organisms belonging to real species. But ultimately, the very first genes on Earth must have a random origin. How else could they originate? They have no ancestors. One genome researcher, Senapathy [6], did computer simulations like the simulations discussed here and has put forward a theory that long ago animals and plants originated in primordial ponds from random DNA genomes. For a few thousand reasons, genomes cannot be created from random DNA fragments ('genes'), and organisms cannot be created from random genomes. The ultimate reason is DNA- or genome centrism: the idea that a genome can create an organism. My next blog will be about 'DNA-centrism'.
Acknowledgements
Rolie Barth contributed the statistical analysis, corrected the draft and made suggestions for improvement. Susan checked my English. Thanks both!
Notes
- Sean R. Eddy (2013) The ENCODE project: Missteps overshadowing a success,
- Personal communication Rolie Barth, author of De kosmos en het leven - een Meesterwerk. (see also: korthof58.htm Note 507). Barth wrote two guest blogs: Circular causality, another secret of life – on the occasion of Philip Ball's How Life Works 25 March 2024. Rolie Barth replies to his critics: What have pufferfishes and plasmas in common? 28 March 2024.
- Christian Schlötterer (2015) Genes from scratch—the evolutionary fate of de novo genes. 2015. Open Access.
- David G Knowles, Aoife McLysaght (2009) Recent de novo origin of human protein-coding genes.
- Brendan R. Camellato, et al (2024) Synthetic reversed sequences reveal default genomic states Open Access. Published: 06 March 2024. "The locus was designed by reversing but not complementing human HPRT1".
- Periannan Senapathy (1994) 'Independent Birth of Organisms. A New Theory That Distinct Organisms Arose Independently From The Primordial Pond Showing That Evolutionary Theories Are Fundamentally Incorrect'. (review).
thanks for sharing and looking forward to your take on DNA centrism
ReplyDeleteThanks. I am working on it!
ReplyDeleteThis feels like a cliffhanger! I'm very much looking forward to the DNA-centrism post.
ReplyDeleteHi Charles, I think I will make a shorter version. It wil be finished sooner... :-)
ReplyDeleteYou also need to take introns into account. Many (most?) of the functional human orphan gene candidates have at least one intron. This is possibly an important feature because exon splicing promotes transport to the cytoplasm where the mRNA can be translated.
ReplyDeleteThe claim that everything between the start and stop codon must be triplet codons is a bit misleading (or lost in translation between human languages). After binding to the mRNA, the reading frame is established by the first ATG that a ribosome comes to. The next codon will be the next three bases after that ATG, and so on. This continues until the ribosome hits a stop codon which causes the ribosome to fall off the mRNA and release it. Once you have a ribosome bound to an ATG, every three bases from that ATG are codons by default.
Hi, thanks for your contribution. In my literature research I missed the fact that "Many (most?) of the functional human orphan gene candidates have at least one intron." I have to investigate whether those candidate orphan genes with introns are real orphan genes.
ReplyDeleteIn the computer simulation: random genes with introns are left out because it is more complex; and the probability to have a functional gene with functional intron splice recognition sites in a random sequence is expected to be very low.
I agree with what you wrote about triplets.
Thanks.
For the evolution of translated genes I suspect the acquisition of splice sites is important for most orphan genes.
ReplyDelete"This has resulted in the identification of over five thousand new multiexonic transcriptional events in human and/or chimpanzee that are not observed in the rest of species. Using comparative genomics, we show that the expression of these transcripts is associated with the gain of regulatory motifs upstream of the transcription start site (TSS) and of U1 snRNP sites downstream of the TSS."
https://pmc.ncbi.nlm.nih.gov/articles/PMC4697840/
The U1 snRNP sites are intron splice sites. The proteins and RNA molecules responsible for intron splicing bind to the proteins responsible for export from the nucleus to the cytoplasm, so this may be an important step in producing a translated gene.
Hi, thanks for your information. This is new for me. Five thousand new orphan genes! If true, that is a whole new chapter in evolution theory. Textbooks chapters about the evolution of genes, gene trees, evolutionary relationships based on gene trees, common descent, etc need to be rewritten/updated... If de novo genes arise in this way in evolution, creationist claims attacking common descent are now debunked.
ReplyDelete