 A schematic view of a DNA molecule built up from like-with-like base pairs James D. Watson (1968) The Double Helix, Penguin 1982 pag. 144. |
 Hiernaast staat een 'fout' model dat Watson en Crick geprobeerd hebben. De 4 bases aan de binnenkant van de helix, maar A paart met A, C met C, etc. Het probleem hiermee was dat een A-A paar veel breder uitvalt dan een T-T paar omdat A breder is dan T. (niet in het model te zien). Daardoor zou de dubbele helix dikker en dunner uitvallen afhankelijk van de base paren. Niet ideaal. In een geniale inval bedacht Watson dat A-T paren en C-G paren ook kunnen en bovendien even breed waren. En dus een zeer regelmatige helix zouden vormen die overal precies even breed was ongeacht de baseparen! Dat zag er veelbelovend uit. En dat model bood nog meer voordelen. Te veel om hier allemaal om te noemen. Lees het boek The Double Helix en U zult voor altijd met andere ogen naar DNA kijken.
Hiernaast staat een 'fout' model dat Watson en Crick geprobeerd hebben. De 4 bases aan de binnenkant van de helix, maar A paart met A, C met C, etc. Het probleem hiermee was dat een A-A paar veel breder uitvalt dan een T-T paar omdat A breder is dan T. (niet in het model te zien). Daardoor zou de dubbele helix dikker en dunner uitvallen afhankelijk van de base paren. Niet ideaal. In een geniale inval bedacht Watson dat A-T paren en C-G paren ook kunnen en bovendien even breed waren. En dus een zeer regelmatige helix zouden vormen die overal precies even breed was ongeacht de baseparen! Dat zag er veelbelovend uit. En dat model bood nog meer voordelen. Te veel om hier allemaal om te noemen. Lees het boek The Double Helix en U zult voor altijd met andere ogen naar DNA kijken.De leukste fout komt nog. De beroemde chemicus en meervoudig Nobelprijswinnaar Linus Pauling heeft in febr 1953, een maand voor Watson en Crick, een fout DNA model gepubliceerd (zie hieronder). Hij wist dat hij moest kiezen uit drie mogelijkheden voor de centrale as: de bases, fosfaat, suiker. Hij kon de bases of suikers niet passend krijgen in de centrale as, dus die vielen af. Dus de fosfaat groepen bleven over als centrale as. De bases waren op de centrale as gemonteerd d.m.v. suikers en staken naar buiten. In zijn model paren de bases helemaal niet met elkaar. Pauling vond het feit dat de bases naar buiten staken een bijkomend voordeel omdat ze dan toegankelijk waren om te koppelen met de aminozuren in een eiwit (zeer speculatief!). Op die manier was een soort relatie van de bases met aminozuren gelegd. Een soort genetische code!
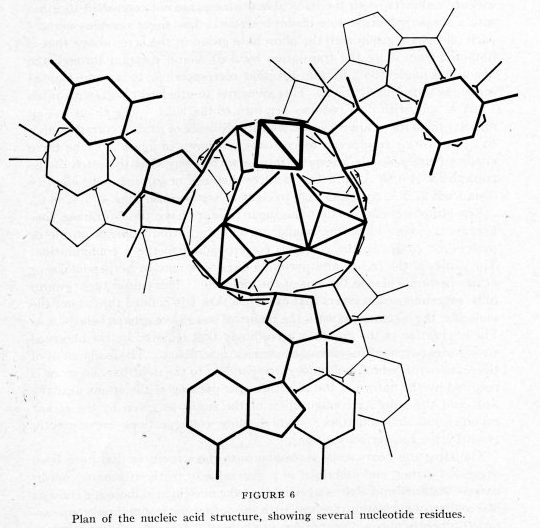 |
| Linus Pauling: A proposed structure for the nucleic acids, PNAS, Febr 1953. DNA binnenste-buiten! (bovenaanzicht) |
Om mij onbekende redenen kwam Pauling bovendien tot drie strengen, 'the triple helix' (zie figuur), in plaats van twee ('the double helix'). Prachtig dat een topwetenschapper, "one of the most influential chemists in history and ranks among the most important scientists of the 20th century" (wiki) en auteur van het handboek The Nature of the Chemical Bond ("one of the most influential chemistry books ever published"), één maand voor Watson en Crick een totaal ander DNA model kon maken! Pauling-DNA! Pauling was tamelijk zeker van zichzelf en publiceerde het. Hij ging voor prioriteit en nam een behoorlijk risico. Voor hem een pijnlijke blunder. Voor ons een bijzonder leerzame fout. Het mooie van Pauling was echter dat hij snel zijn fout in zag en Watson en Crick alle eer gaf. Dat is nog eens een topwetenschapper: fout maken en fouten toegeven!
Waarom ging Pauling in de fout?
Hij wilde graag een DNA model bouwen, maar had nog niet voldoende data. Daarentegen hadden Chargaff en Rosalind Franklin wel data geproduceerd, maar waren niet geïnteresseerd in modellen bouwen. Watson en Crick wilden graag een DNA model bouwen, hadden geen zelf geproduceerde data, maar beseften dat hun poging waardeloos was zonder goede data. En ze deden hun uiterste best om die data te pakken te krijgen. En ze legden hun ideeën voor aan experts in hun directe omgeving. Wat hen voor fouten behoedde. Dat maakte hen tot topwetenschappers.Wat is DNA toch een waanzinnig mooi molecuul! Ik raak er niet over uitgepraat!
De illustratie en publicatie heb ik gevonden op de website 'Linus Pauling and the Race for DNA'. Daar staat een heel aardige, instructieve inleiding (minicursus) over de ontdekking van DNA en de rol van Pauling.
Vorige blogs over DNA
- Als DNA perfect is, waarom dan dood, erfelijke ziekte, kanker? 23 Jan 2012
- Waarom DNA en geen RNA als erfelijkheids molecuul? 19 Jan 2012
- Waarom DNA? (3) Optimale DNA structuur door Natuurlijke Selectie?16 Jan 2012
- Waarom DNA? (2) Alternatief DNA 12 Jan 2012
- Waarom DNA? 10 Jan 2012
- Waarom Rosalind Franklin de Nobelprijs niet kreeg 9 dec 2007
Postscript
19 Feb 2023
In de nieuwste editie van het evolutie studieboek Futuyma, Kirkpatrick (2023) ontbreekt een afbeelding van de dubbele helix! DNA wordt wel kort beschreven in de tekst... Dit terwijl er wel een plaatje van de dubbele helix in een oudere editie stond. Zie: New evolution textbook as birthday present for Darwin, 12 Feb 2023


